
Sending AWX Tower Backups to S3 Bucket Guide
Published:
AWX Backup Guide
This guide will walk you through the process of creating backups for your AWX installation.
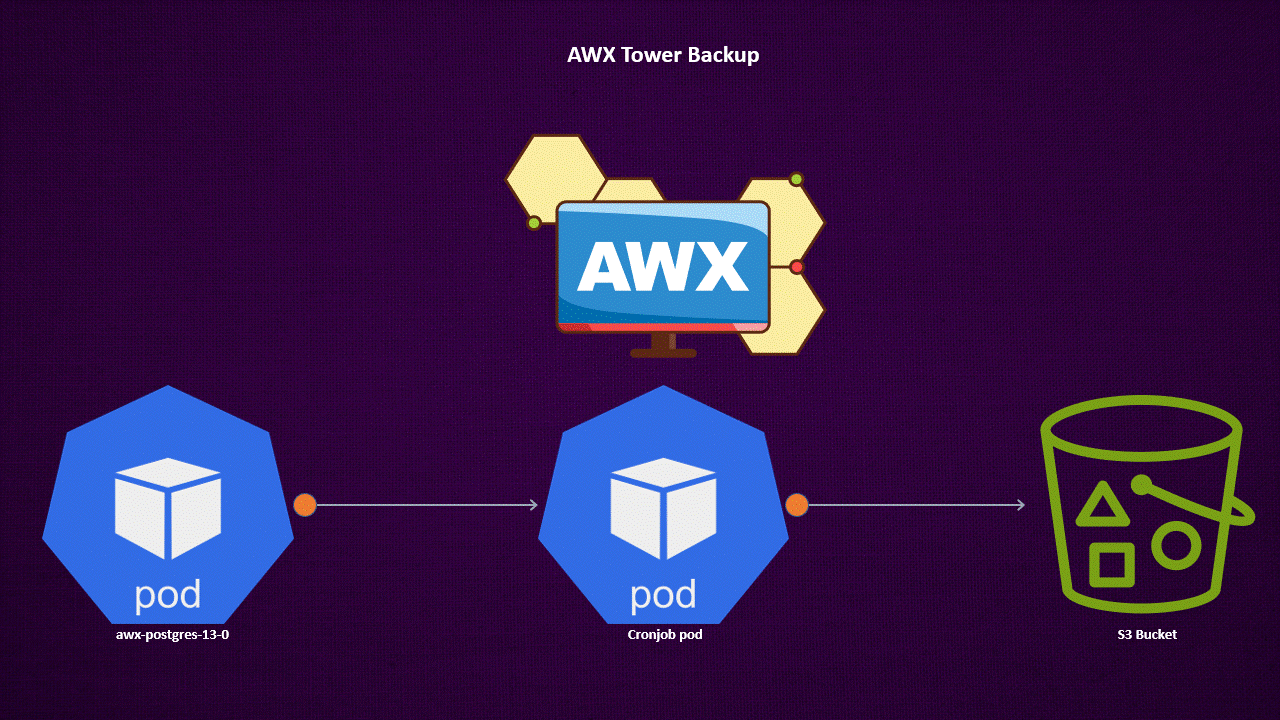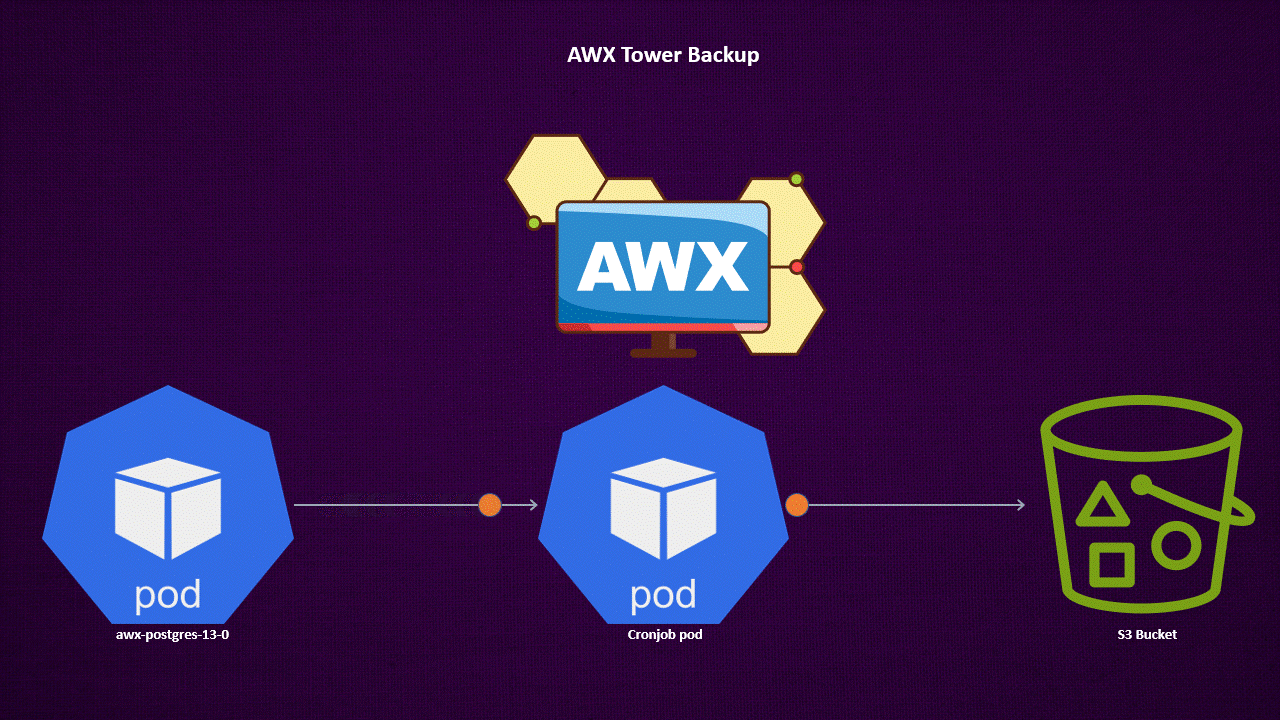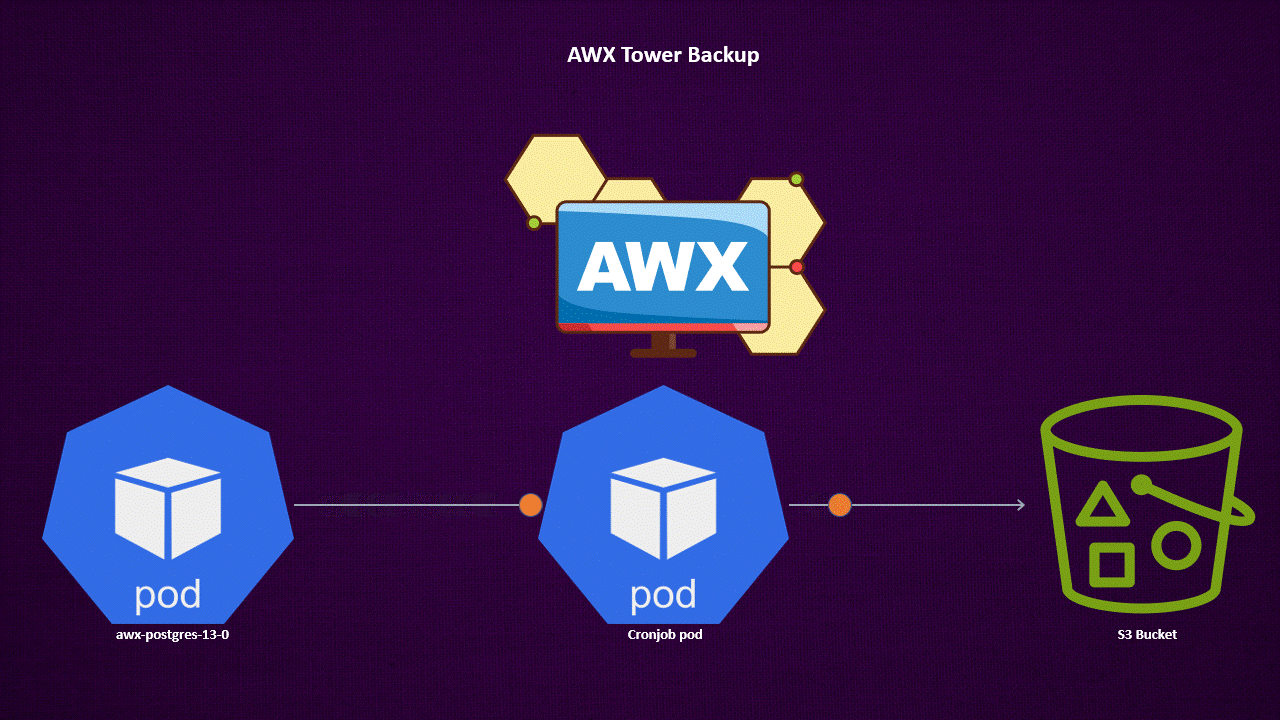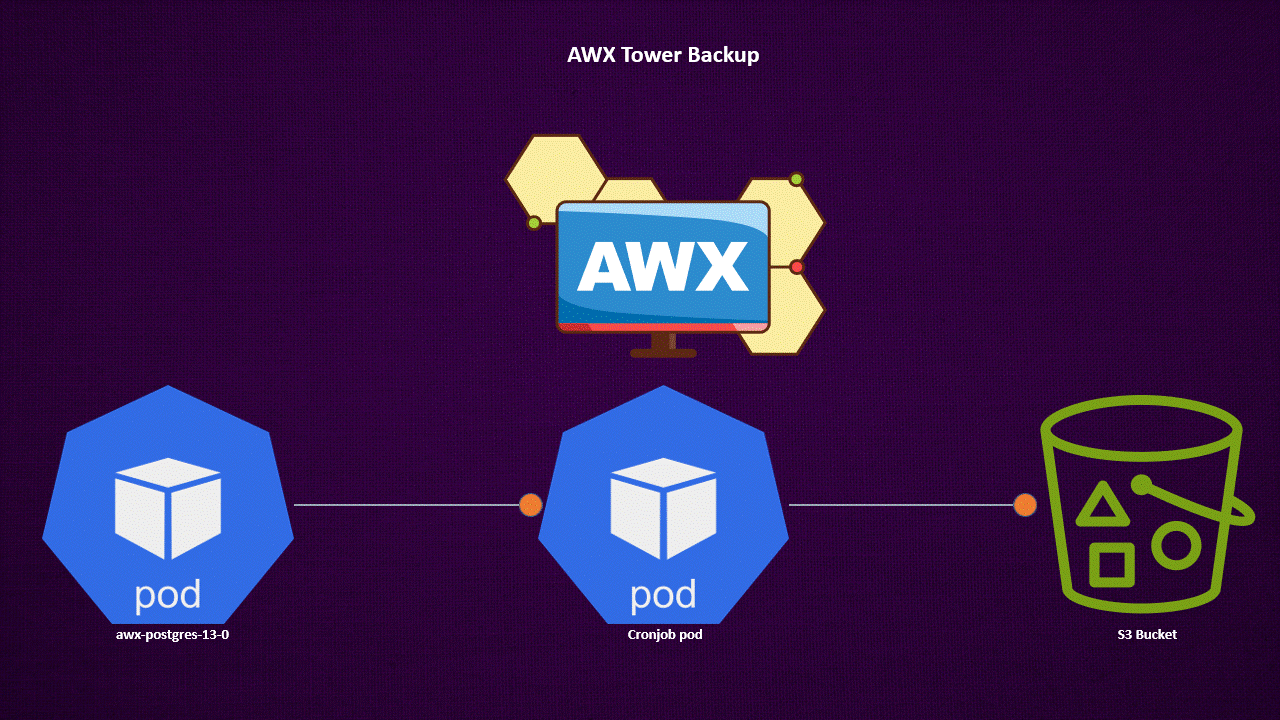
Table of Contents
Prerequisites
Before you begin, make sure you have the following:
- AWX Tower running on a Kubernetes cluster.
kubectlcommand and proper privileges to access the cluster.- Docker Registry (e.g., Harbor, Docker Hub).
- Backup storage (e.g., S3, Git).
- Kubernetes secrets for S3 bucket access.
Backup Procedure
Creating backups for your AWX Tower installation is crucial to ensure the safety and availability of your data. In this section, we will guide you through the step-by-step process of taking backups efficiently.
PostgreSQL Database Backup
The backbone of your AWX Tower installation is its PostgreSQL database, where all your configurations, job history, and other critical data are stored. Taking regular backups of this database is essential for disaster recovery and data integrity.
To create a backup of the PostgreSQL database, you can use the pg_dump command provided by PostgreSQL. Here’s how you can do it:
kubectl exec -it awx-postgres-13-0 -- pg_dump -h awx-postgres-13.awx.svc.cluster.local -U $PGUSER $PGDB > awx-$(date "+%Y-%m-%d").dump
This command dumps the PostgreSQL database. To automate this process, consider using a CronJob to periodically create and push backups to a backend like an S3 bucket.
Python Script for S3 Upload
Save the following Python script as app.py. Place it in the same directory as the Dockerfile provided. You can also run the script directly.
python app.py --item-name=awx-$(date "+%Y-%m-%d").dump --access-key=$ACCESS --secret-key=$SECRET --endpoint-url=$ENDPOINT
import argparse
import boto3
# Argümanları analiz et
parser = argparse.ArgumentParser(description='S3 upload script')
parser.add_argument('--access-key', required=True, help='HCP access key')
parser.add_argument('--secret-key', required=True, help='HCP secret key')
parser.add_argument('--endpoint-url', required=True, help='Hitachi HCP endpoint URL')
parser.add_argument('--item-name', required=True, help='name')
args = parser.parse_args()
# Create a session using the access key and secret key
session = boto3.Session(
aws_access_key_id=args.access_key,
aws_secret_access_key=args.secret_key
)
# Create an S3 client with the custom endpoint URL
s3_client = session.client('s3', endpoint_url=args.endpoint_url, verify=False)
# Upload file
try:
response = s3_client.upload_file(args.item_name, 'awx_backups', args.item_name)
print("Upload successful.")
except Exception as e:
print(f"Error uploading file: {str(e)}")
Container for Backing Up AWX Tower PostgreSQL from Remote
You can use the docker file below to build a container. I’ve pushed it to harbor as docker registry. It uses postgres image and it has python functionallity.
FROM postgres:13-alpine3.17
RUN apk add --no-cache ca-certificates
RUN apk add py3-pip
RUN pip install boto3
COPY app.py app.py
RUN update-ca-certificates
Kubernetes Secret for S3 Credentials
Generate a Kubernetes secret for S3 credentials by running the following command, replacing placeholders with your own values:
kubectl create secret generic my-secret --from-literal=access-key=$YOURACCESSKEY --from-literal=secret-key=$YOURSECRETKEY --from-literal=endpoint=$YOURENDPOINTFORS3 -o yaml --dry-run=client > secret.yaml
Kubernetes CronJob for Scheduling Backup Tasks
This CronJob runs at 1 AM daily, backing up the PostgreSQL database and pushing it to an S3 storage location. You need to edit the CronJob image registry with your image registry.
kubectl apply -f cronjob.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: awx-pg-backup
namespace: awx
spec:
schedule: "0 1 * * *"
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 0
jobTemplate:
spec:
ttlSecondsAfterFinished: 10
template:
spec:
containers:
- name: postgres
image: yourimageregistry/postgres:13-alpine3.17
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- |
pg_dump -h awx-postgres-13.awx.svc.cluster.local -U $PGUSER $PGDB > awx-$(date "+%Y-%m-%d").dump
sleep 10
python app.py --item-name=awx-$(date "+%Y-%m-%d").dump --access-key=$ACCESS --secret-key=$SECRET --endpoint-url=$ENDPOINT
env:
- name: PGDB
valueFrom:
secretKeyRef:
key: database
name: awx-postgres-configuration
- name: PGUSER
valueFrom:
secretKeyRef:
key: username
name: awx-postgres-configuration
- name: PGPASSWORD
valueFrom:
secretKeyRef:
key: password
name: awx-postgres-configuration
- name: ACCESS
valueFrom:
secretKeyRef:
key: access-key
name: s3-bucket
- name: SECRET
valueFrom:
secretKeyRef:
key: secret-key
name: s3-bucket
- name: ENDPOINT
valueFrom:
secretKeyRef:
key: endpoint
name: s3-bucket
restartPolicy: OnFailure
Conclusion:
In this guide, we have outlined the process of automatically sending AWX Tower backups to an Amazon S3 bucket. By leveraging Kubernetes CronJobs, a Python script, and AWS S3, you can ensure regular and automated backups of your AWX Tower’s PostgreSQL database. This approach enhances data protection and simplifies the backup management process. With the backup strategy in place, you can have peace of mind knowing that your AWX Tower data is securely stored and easily restorable.
Thank you for following this guide, and we hope it proves valuable in safeguarding your AWX Tower data.